

























Close
Autor tekstu eksperckiego: Paweł Rybka
Data Science and Machine Learning branches grow so fast nowadays, that many people consider them to be some kind of black magic. Skimming through numerous artificial intelligence manuscripts I felt like a sorcerer myself – so many lines of incomprehensible symbols and graphs which would only make me dizzy. I thought to myself that if I struggle with understanding those concepts so much as a data scientist, someone with no experience will be even more confused. Then I came up with an idea – you do not have to be an excellent cook to prepare a delicious meal – all you need to do is gather the ingredients and follow the recipe. This short cooking course will teach you how to brew your first Gaussian Mixture!

[https://images.pexels.com/photos/4355630/pexels-photo-4355630.jpeg]
To get an idea of how to prepare our elixir, first, we need to understand how the potion is supposed to work. Gaussian Mixture Models (GMMs) are clustering methods that provide one-hot encoded labeled vectors at the output. To put it simply, we want our mixture to detect how much of a certain phenomenon occurs in a particular observation. Imagine four different vehicles – bicycle, car, boat, and plane. Each of those machines may be represented as a vector:
Each of the numbers in the output vector denotes how much of a certain vehicle is “present” in the observed machine. For all those representative classes (bicycle, car, boat, plane) the task is simple – just put “1” in the column standing for these certain means of transport. The problem starts when the vehicle does not belong to any of those classes. Imagine a motorcycle – it has two wheels just like a bike and a motor running on petrol just like a car. Additionally, it cannot fly like a plane nor sail like a boat so we can say that this motorcycle is a mixture of car and bicycle. Assuming that the given motorcycle is similar to a car a little bit more than a bicycle, our output vector may be denoted as [0.6, 0.4, 0.0, 0.0]. Similarly, imagine a glider plane – it has two wheels like a bike, runs on the wind like a sailboat, and is a flying vehicle just like a jet. Combining this knowledge, we would result in having an output vector like: [0.1, 0.0, 0.2, 0.7] as the glider shares the majority of features with a jet and none with a car.
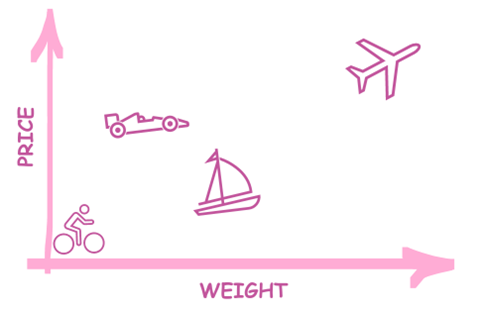
I hope now you got an idea of how classifiers are supposed to work. But how do they work? Well, they use pretty much the same tools as we do when figuring out values to put in the output vector – the knowledge of similarities and differences between certain objects. Those similarities and differences are represented by input vectors which may hold such features as top speed, length, weight, engine power, or price.
For example, Formula One racing car which reaches 360 km/h (225 mph), has a total length of 5.6 m, weights 800 kg (about 1763.7 lb.), and costs around USD 15 million produces an input vector of [360.0, 5.6, 800.0, 15000000.0], meanwhile, the input vector of Variant 100 Boeing 737 looks like this: [648.2, 28.65, 38.555.0, 31100000.0]. The figure presented below shows how two values (price and weight) of our four-valued input vector may look like on a 2D plot.
Humans, based on their life-based knowledge, are capable of making assumptions about what certain vectors may stand for, for example, it’s not so difficult to figure out that [50.0, 1.75, 10.0, 200.0] stands for a bicycle. Machines, on the other hand, must be provided with sets of input and output vectors to distinguish certain groups from one another.

When have collected data (input + output vectors set – e.g. [50.0, 1.75, 10.0, 200.0]: [1, 0, 0, 0]) which represents several hundred vehicles, our classifier is ready to be trained!
But there arises one problem – for classifying data, we need to know our output vectors values. But what if we do not know anything about classes that we want to distinguish from one another? This is the time when GMM comes into play!
Imagine that you are a plant nursery owner and want to automate your company. The automation engineer told you your field should be divided into 3 subfields to reach the maximum efficiency of his solution. His system allows you to adjust the temperature, air humidity, and frequency of plant irrigation. To assure the best environment for each plant, you have to divide all your plants into 3 subgroups and then select optimal system setpoints for each of those groups.
To start with, we need to understand how GMM cluster data – searches for a denoted number of clusters (in our case 3) and fits Gaussian distributions into them. To simplify the explanation of how GMM works let’s consider one of the parameters at once:
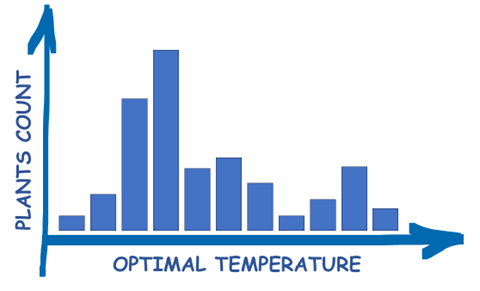
The presented plot shows how many of our plants prefer certain temperatures. To optimally divide those plants into 3 subgroups for which the temperature will be individually set, we fit Gaussian distribution into this data as follows:
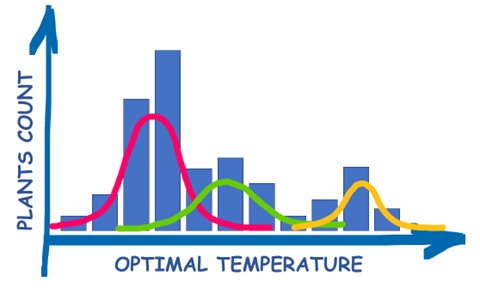
After fitting the data, we can predict class membership for each plant, so we know in which subfield we can plant it. The output vector would look like this:
[class 1 compatibility, class 2 compatibility, class 3 compatibility]
As you can see, we now also know how much certain plant fits other classes as well, so in case of overloading one subfield with too many plants, you can move some of them to a neighboring field without harming their optimal environment so much! For example, a plant with its output vector [0.5, 0.4, 0.1] may be freely moved from subfield 1 to subfield 2 without being unnecessarily exposed to harmful conditions, while moving it to subfield 3 may result in its withering.
We have performed one dimensional value analysis for visualization purposes, but of course, GMM works with input vectors of any length. We can add humidity and irrigation frequency to the model and it will still be able to assign certain plants to 3 classes.
The last thing we need to get is setpoints. As you remember, the automation engineer asked us to provide certain values of temperature, humidity, and irrigation frequency to be maintained in particular subfields. Thankfully, GMM provides clusters’ parameters such as mean values and covariances of mixture components. The mean values denote the center of our distributions for each parameter and can be directly transferred to the automation system as setpoints!
As you can see, brewing our Gaussian Mixture was not so hard at all!
If you enjoyed our cooking tutorial, stay tuned for more as our alchemist lab has a lot more secrets yet to be revealed!
References:
