


























Close
Autor tekstu eksperckiego: Piotr Rożek
Many optimization problems in everyday life involve finding the minimum or maximum value of a function. For example, if we want to find the shortest path between two points, we look for the minimum of the distance function. If we want to buy something at the lowest price, we look for the minimum of the cost function. If we want to get the best score on an exam, we look for the maximum of the grade function. Optimization is also at the heart of machine learning, where training involves finding the model that best fits the data, so minimizing the error or loss between the model’s predictions and the actual data. If the definition of “best” is based on a loss function, then training can be viewed as a minimization problem since the optimal model corresponds to the lowest loss. You might have encountered loss functions like cross entropy (used for classification) or mean squared error (used for regression). In this article, we will try to understand the basics of two effective optimization techniques – gradient descent and Newton’s method, and will see how they are used with boosting to create very effective ensemble methods in machine learning, gradient boosting and XGBoost.
But first, imagine you are trying to find the treasure hidden in the lowest point in a valley. You have two tools: a compass and a map. The compass tells you the direction of the steepest slope at your current position, while the map shows you the curvature of the terrain around you. Newton descent is like using both the compass and the map to find the best direction to move. Gradient descent is like using only the compass and hoping for the best.

Gradient descent uses the first-order derivative, also known as the gradient vector, to update the parameters in the opposite direction of the gradient. The gradient measures the local slope of the function surface. It points in the direction of steepest ascent. To find minimizers using gradient information, we have to travel in the opposite direction of the gradient. If you keep going in this direction, you’ll eventually reach a local minimizer (the treasure!). Newton’s descent, on the other hand, is a method of finding the minimum of a function by using its second-order derivative, also known as the Hessian matrix.
Let’s dive into more details. The gradient descent procedure is quite a simple process. We begin by initializing our solution, which can be either a random or a more sophisticated guess. After that, we calculate the negative gradient from the initial guess to determine the direction we should move. We then compute the step length, which tells us how far we should move in the direction of the negative gradient. It is important to calculate the step length (it is a learning rate!) to ensure that we do not overshoot the solution. We can update our solution guess to a new point by taking a step in a particular direction and distance. After reaching this new point, we check for convergence, that is whether the solution doesn’t change much between consecutive iterations. If we have converged, then we have found a local minimizer. If not, then we iterate again from this new point.
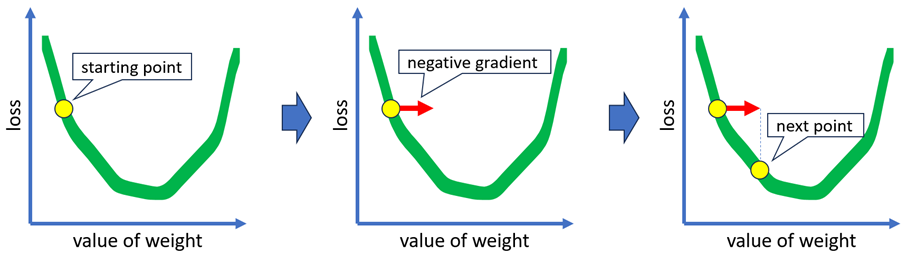
The Newton’s method procedure has two key differences: we determine the descent direction by computing the gradient and Hessian, which involves using both first- and second-derivative information, and we skip the computation of the step length.
When using gradient descent, first-derivative information can only be used to create a local linear approximation. Although this approximation provides a descent direction, different step lengths can lead to significantly different estimates and may ultimately slow down convergence. By incorporating second-derivative information, Newton’s method enables us to create a local quadratic approximation. This additional information results in a superior local approximation, leading to better steps and faster convergence.
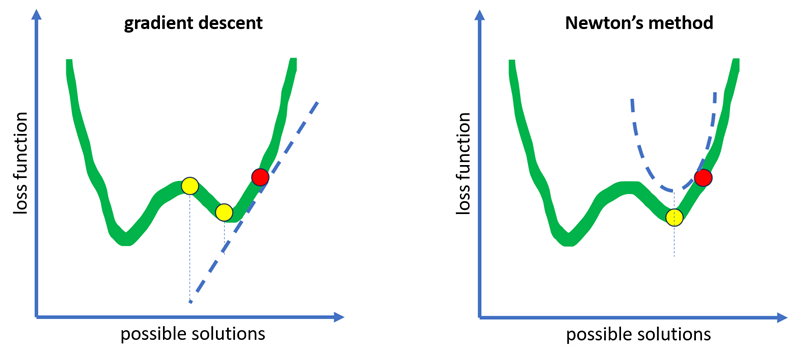
The difference between the two methods is that Newton descent can converge faster and more accurately to the optimal solution, but it requires more computation and memory, since it needs to calculate and store the Hessian matrix. Gradient descent is simpler and more scalable, but it may take longer and stuck in local minima.
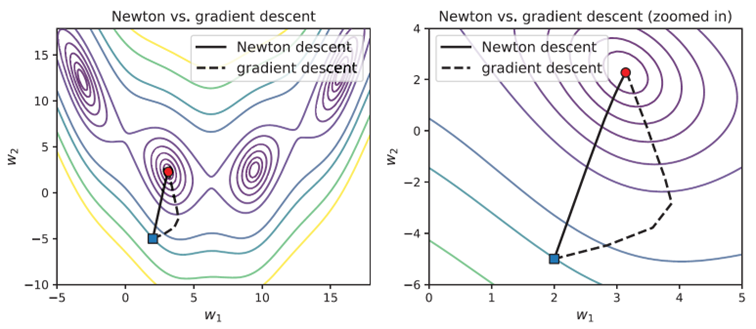
Gradient descent and Newton’s method are both used with boosting. In gradient boosting, we aim to train a sequence of weak learners that can estimate the gradient at each iteration, and gradient of the loss function is a measure of the misclassification. Examples that are classified incorrectly will have large gradients as the difference between the actual and predicted labels (residuals) will be significant. Conversely, examples that are classified correctly will have small gradients. In gradient descent, the negative gradient is used directly, whereas in gradient boosting, a weak regressor is trained over the residuals to estimate the gradient. In Newton boosting the gradients of the loss function are also calculated (the first derivative), but they are weighted. The weights are computed using the Hessian of the loss function (the second derivative). However, the computation of the Hessian can be computationally expensive. Newton boosting avoids this expense by learning a weak estimator over the individual gradients and Hessians.
Both gradient descent and Newton’s method are two powerful techniques used for minimizing the loss function. And that’s what machine learning is all about: finding the sweet spot that makes your model happy. Thank you for reading this article, and I hope you learned something new today.
References:
[1] Gautam Kunapuli – Ensemble Methods for Machine Learning, Manning Publications Co., 2023
[2] What is gradient descent? https://www.ibm.com/topics/gradient-descent
[3] Reducing Loss: Gradient Descent. https://developers.google.com/machine-learning/crash-course/reducing-loss/gradient-descent
