

























Close
Autor tekstu eksperckiego: Paweł Sobel, Data Scientist
Jednym z pierwszych data scientistów, który zwrócił uwagę na problem dryfu danych (ang. data drift) był żyjący około 2500 lat temu Heraklit z Efezu. Dostrzegł on, że zmiana jest jedynym stałym składnikiem rzeczywistości. Jednak jak to filozoficzno-humorystyczne odniesienie ma się do danych i uczenia maszynowego? Kto choć raz zbudował model, a następnie wykorzystywał go w dłuższym okresie zapewne już dobrze wie o co chodzi. Niemal każdy model z czasem traci na aktualności, a co za tym idzie obniża swoje zdolności predykcyjne. Dryf danych jest zatem zjawiskiem powodującym obniżenie skuteczności modeli w czasie.
Kilka przykładów modeli dziedzinowych oraz zmian, które wpływają na pogorszenie jakości prognoz najlepiej zobrazuje problem dryfu:
Taksonomia
Biorąc po uwagę różne rodzaje dryfu wyróżnia się:
W przypadku modeli biometrycznych najczęściej mamy do czynienia z ostatnim typem dryfu. W zależności od charakterystyki i tempa zmian koncepcji wyróżniamy:
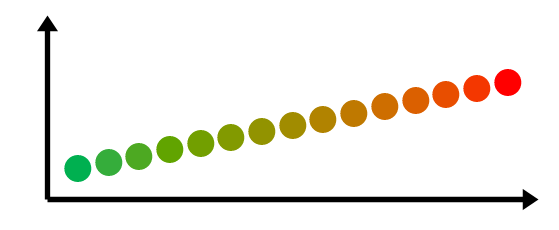
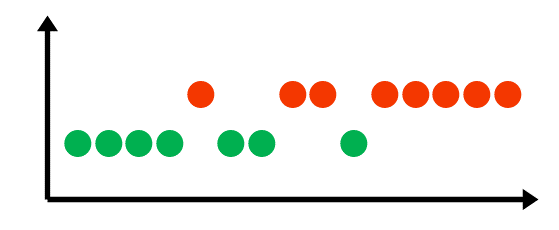
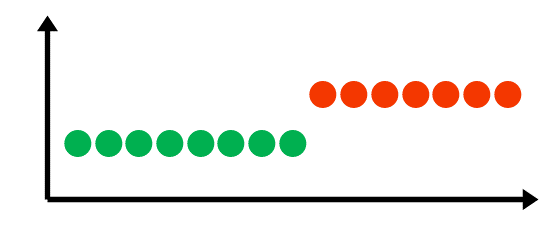
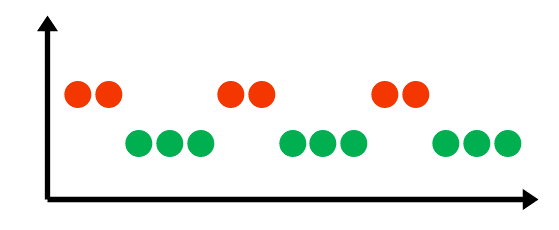
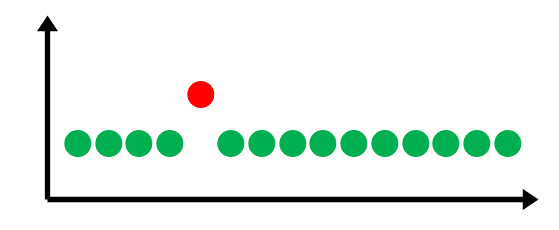
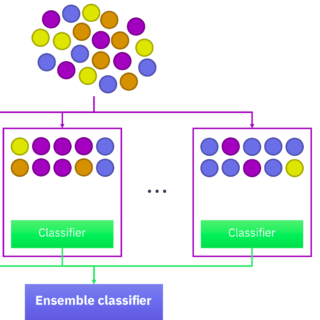
Wykrywanie dryfu koncepcji
Wiedząc czym dryf jest i jakie są jego rodzaje warto zastanowić się w jaki sposób go wykrywać. Podejście eksperckie bazujące na znajomości swojej dziedziny lub biznesu polegać będzie na reagowaniu na występujące zmiany. Reorganizacja przestrzeni sprzedażowej w sklepie będzie miała duży wpływ na zmianę reguł zakupowych klientów. Wprowadzenie nowej wersji strony internetowej zmieni user experience, a tym samym wpłynie na zachowania użytkowników. Tego typu wydarzenia będą najprawdopodobniej wymagały budowy nowych modeli bazujących jedynie na najświeższych danych. Innym sposobem wykrywania dryfu są podejścia bazujące na analizie danych lub zastosowaniu uczenia maszynowego:
Osobom korzystającym z pythona w detekcji dryfu (i nie tylko!) pomogą następujące biblioteki:
Radzenie sobie z dryfem
Wykrycie dryfu wiąże się z koniecznością poradzenia sobie z nim lub przynajmniej zniwelowania jego wpływu. Zrobić to można na kilka sposobów:
Wymienione podejścia do opanowania dryfu to zaledwie kilka bazowych rozwiązań. W rzeczywistości należy sobie również zadać pytanie jaki jest odpowiedni zakres danych, z których model każdorazowo jest budowany. Niektóre dane historyczne nie wnoszą nic wartościowego do modelu, a jedynie zwiększają złożoność obliczeniową. Stopniowe “wyłączanie” starszych sekwencji danych w oparciu o metryki dryfu może pomóc w budowie odpowiedniego systemu. Działania podjęte w celu poradzenia sobie ze zmianami wzorców będą również zależne od typu problemu, z którym się borykamy. Pracując na niezbalansowanych zbiorach danych dobrym rozwiązaniem będzie nadpróbkowanie (ang. oversampling) klasy mniej licznej ze szczególnym uwzględnieniem najświeższych danych poprzez nadanie im odpowiednio wyższych wag prawdopodobieństwa wylosowania.
Dryf danych jest ściśle związany z budową i utrzymaniem modeli uczenia maszynowego. Do jego wykrycia konieczne jest monitorowanie systemu. Zmiany w rozkładach danych lub obniżenie efektywności predykcji mogą świadczyć o wystąpieniu dryfu. Sposoby radzenia sobie z nim są uzależnione od siły zmian i charakterystyki problemu, z którym się mierzymy. Istotne jest odpowiednio częste aktualizowanie modeli i szybkość reakcji. Dryf można opanować gdy tylko pozna się jego specyfikę i odpowiednio zaprojektuje system uczenia modeli.
Źródła:
[1] J. Lu, A. Liu, F. Dong, F. Gu, J. Gama and G. Zhang, „Learning under Concept Drift: A Review,” in IEEE Transactions on Knowledge and Data Engineering, vol. 31, no. 12, pp. 2346-2363, 1 Dec. 2019, doi: 10.1109/TKDE.2018.2876857.
[2] Gemaque, RN, Costa, AFJ, Giusti, R, dos Santos, EM. An overview of unsupervised drift detection methods. WIREs Data Mining Knowl Discov. 2020; 10:e1381. https://doi.org/10.1002/widm.1381
[3] https://miroslawmamczur.pl/czym-jest-i-jak-zbadac-dryft-modelu-model-drift/
