


























Close
Jednym z największych wyzwań w pracy analityka jest stworzenie dobrego modelu. Jak ocenić czy model jest dobry? Poprawna odpowiedź brzmi: to zależy. Zależy od wielu czynników, a w tym artykule krótko przedstawię w jaki sposób my, Data Scientiści z Digital Fingerprints, tworzymy i oceniamy jakość naszych modeli Machine Learningowych.
Model dedykowany tylko Tobie
https://www.clipartkey.com/view/TwwoJh_hands-typing-on-keyboard-icon-icon-typing-on/
Wyobraź sobie, że piszesz na klawiaturze. Robisz to bez skupiania się na tej czynności. Osoby, które na co dzień korzystają z komputera nawet nie patrzą na klawiaturę podczas pisania. Z kolei osobe starsze, na przykład Twoi rodzice, zazwyczaj robią to zdecydowanie wolniej i poświęcają na to więcej czasu. Tempo pisania, czas przejścia pomiędzy klawiszami, czas wciskania każdego z klawiszy – wszystkie te niepozorne liczby stanowią dla nas cenną informację. Są to dane, które stanowią wsad do zaprojektowania Twojego unikalnego modelu. Gdy zgromadzimy ich wystarczającą ilość, dane ulegają pewnym transformacjom, aż przychodzi pora na …
Trening Twojego modelu
Załóżmy, że wykonałeś 8 logowań do bankowości online w Twoim banku. Hipotetycznie jesteśmy już w stanie zaproponować Ci model, który będzie rozpoznawał, czy logujesz się Ty, czy inna osoba, którą nazywamy fraudem.
Do treningu takiego modelu potrzebujemy Twoich danych. Ale nie są to dane poufne – nie gromadzimy informacji o tym, co wpisujesz, zatem nie znamy Twojego loginu, hasła czy danych do przelewu. Skupiamy się wyłącznie na sposobie w jaki to robisz. Zwracamy uwagę np. na czas przejścia pomiędzy klawiszami, jak było wcześniej wspomniane. Następnie bierzemy takie dane również od innych, losowo wybranych użytkowników. Są to Twoje kontrprzykłady. Dzięki ich wykorzystaniu algorytm klasyfikujący może się nauczyć odróżniania Twojego zachowania od zachowań innych. Później przekształcamy te dane tworząc features. Teraz przyszła pora na trening Twojego modelu. Podczas tego procesu algorytm szuka pewnej linii, która będzie w stanie oddzielić Twoje obserwacje od pozostałych. Odbywa się to na wielu płaszczyznach, ich ilość jest zdeterminowana przez przekształcenie danych. Jakie dopasowanie, mówiąc inaczej jaką linię powinniśmy uważać za odpowiednią? Rozważmy trzy scenariusze:
https://medium.com/@srjoglekar246/overfitting-and-human-behavior-5186df1e7d19
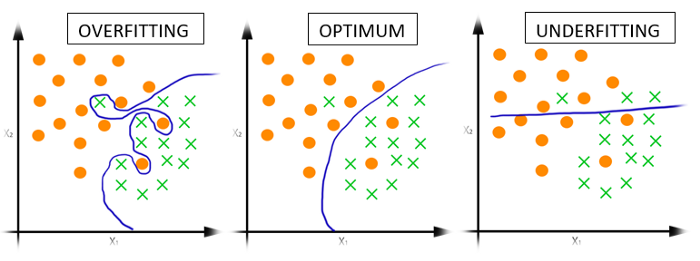
Niech pomarańczowe kropki stanowią kontrprzykłady, zaś zielone krzyżyki to Twoje obserwacje.
1. Overfitting. Algorytm znalazł linię, która poprawnie oddziela wszystkie Twoje obserwacje od kontrprzykładów. Pozornie jest to sytuacja idealna. Jednakże my wiemy, że model zbyt dobrze dopasował się do Twoich treningowych obserwacji, co powoduje każda nowa może zostać źle sklasyfikowana. A przecież zależy nam na tym, aby ten model działał w rzeczywistości, a nie tylko podczas treningu. Pamiętasz, jak podczas egzaminu na studiach byłeś nauczony tylko na egzaminy z poprzednich lat? Doskonale znałeś klucz odpowiedzi, był niezmienny od kilku lat… Tymczasem profesor postanowił ułożyć nowy egzamin i okazuje się, że znasz odpowiedzi tylko na nieznaczną część pytań. To jest właśnie przypadek zbyt mocnego dopasowania.
2. Optimum. Jak się można domyślić, to jest pożądana sytuacja. Model potrafi poprawnie sklasyfikować większość obserwacji. Popełnia błędy, jak każdy z nas, ale ich ilość nie jest znacząca. Właśnie taka sytuacja na danych treningowych stanowi dla nas przesłankę, że model nie pogubi się w rzeczywistości i będzie w stanie rozpoznać Twoje kolejne logowanie. Tak było wtedy gdy byłeś nauczony na egzamin.
3. Underfitting. Tutaj sprawa jest prosta. Widzimy, że model zupełnie sobie nie radzi, już na etapie treningu. Popełnia zbyt dużo błędów, ponieważ jest zbyt prosty. Odwołując się do sytuacji ze studiów, to przypadek kiedy byłeś na egzaminie kompletnie nieprzygotowany – nie zerknąłeś nawet na testy z poprzednich lat. Strzelisz poprawnie kilka odpowiedzi, ale nic poza tym.
W jaki sposób oceniamy Twój model?
Wytrenowanie modelu to tylko początek naszej pracy. Trzeba go jeszcze rzetelnie ocenić. W tym celu już na samym początku (przed treningiem) w istniejących danych wydzielamy podzbiór, stanowiący zazwyczaj ok. 30% wszystkich obserwacji, na którym oceniamy model. Ten proces nazywa się walidacją modelu. Wydzielony podzbiór nie uczestniczy w treningu modelu. Zanim przejdziemy do konkretnych metryk za pomocą których oceniamy modele, rozszerzmy przykład ze studiami.
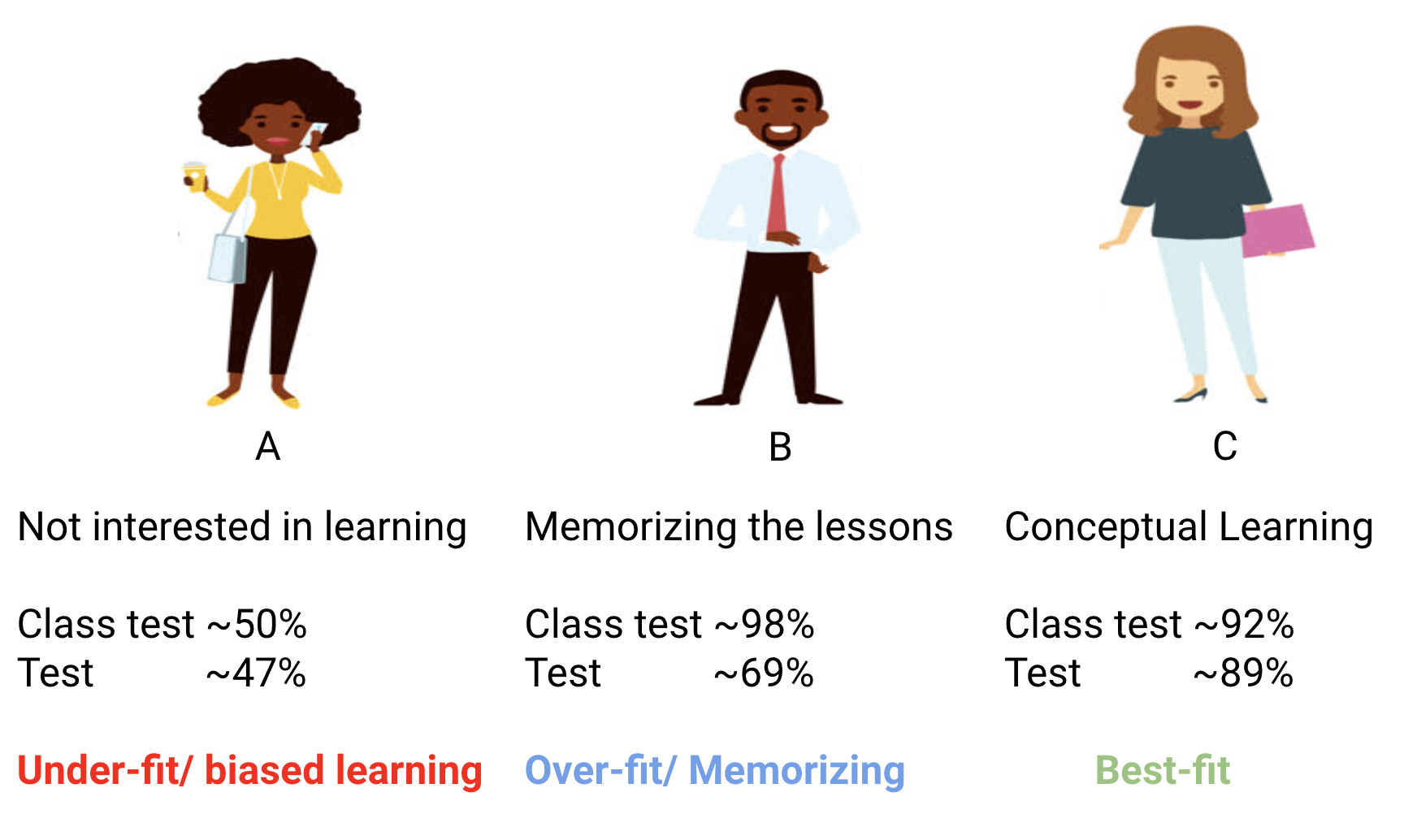
Niech opisane wcześniej (w akapicie „Trening Twojego modelu”) sytuacje egzaminów staną się zwykłym, mniejszym sprawdzianem z przedmiotu. Ten sprawdzian nie determinuje ostatecznej oceny z przedmiotu (na powyższej grafice są to wartości oznaczone „Class test”). Najlepszy wyniki na sprawdzianie uzyskała osoba z przypadku B. Z kolei podczas prawdziwego egzaminu (na grafice „Test”) ta osoba wcale nie ma najlepszych rezultatów. Była, najprościej mówiąc, przeuczona – albo uczyła się tzw. „na blachę”, czyli bez zrozumienia, albo miała odpowiedzi od wcześniejszych roczników na sprawdzianie. Podczas egzaminu nie miała tyle szczęścia. Najlepszy wynik uzyska osoba, która ma pewien, dobrze dobrany schemat uczenia, który działa zarówno w przypadku sprawdzianu, jak i ostatecznego egzaminu. Tego właśnie oczekujemy od naszego modelu – aby potrafił poprawnie sklasyfikować dane, których wcześniej nie widział, czyli na etapie walidacji modelu. Innymi słowy, aby był dobry niezależnie od warunków.
Accuracy – najczęściej stosowana metryka do oceny modeli, czy może coś innego?
No dobrze, teoretycznie wiemy który model będzie najlepszy, gdy mamy do wyboru kilka skrajnie różnych wariantów. Ale nie będziemy przecież naocznie sprawdzać wyników treningu każdego z Twoich modeli, zapamiętywać i wybierać najlepszy – nie na tym polega Machine Learning! Dlatego tutaj trzeba wprowadzić posługiwanie się pewnymi metrykami, czyli miarami, za pomocą których ocena modeli może odbywać się automatycznie. Predykcję modelu, czyli to jak sprawdza się na zbiorze walidacyjnym, można przedstawić za pomocą macierzy błędów (confusion matrix). Przeanalizujmy taką sytuację: załóżmy, że zgromadziliśmy 240 obserwacji od Ciebie i 2760 obserwacji od innych użytkowników (są to przykładowe liczby).
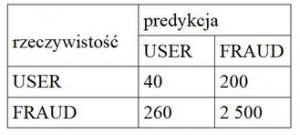
Z powyższej tabeli możemy policzyć różne metryki:
• Dokładność (ang. accuracy) to iloraz sumy poprawnie sklasyfikowanych obserwacji (40 + 2500) i wszystkich obserwacji (3000). W tym przypadku wynosi w przybliżeniu 85%. Im wyższa wartość accuracy, tym lepiej, dlatego model ten wydaje się być dobry.
Na tym można by poprzestać, gdyby nie fakt, że nasze klasy nie są równoliczne! Twoje obserwacje stanowią mniejszość danych. Sugerowanie się accuracy tutaj nie zadziała. Dlatego my patrzymy na inne wskaźniki, między innymi takie jak:
• Czułość (ang. sensitivity), czyli iloraz poprawnie sklasyfikowanych obserwacji należących do klasy 1 (użytkownik) i wszystkich obserwacji należących do klasy 1. Czułość tego modelu to 17%. Dość mało, nieprawdaż?
• Specyficzność (ang. specificity), czyli iloraz poprawnie sklasyfikowanych obserwacji należących do klasy 0 (obserwacje innej osoby, kontrprzykłady) i wszystkich obserwacji należących do klasy 0. Specyficzność tego modelu wynosi 91%. Wysoko, ale zwróćmy uwagę na to, że model w większości sytuacji nie rozpoznał Twoich obserwacji…
Dlatego tak ważne jest by wiedzieć, na co zwracać uwagę podczas oceny modelu. W naszym rozwiązaniu wykorzystujemy funkcję celu odporną na nierównoliczność klas.
To nie są wszystkie tajniki naszego rozwiązania, ale o tym opowiemy Wam w innym artykule.
A co gdy Twoje zachowanie się zmieni?
 https://fingerprints.digital/wp-content/uploads/2022/08/system-integration.jpg
https://fingerprints.digital/wp-content/uploads/2022/08/system-integration.jpg
Wszystko pięknie działa, masz już przygotowany swój model, który rozpoznaje, gdy logujesz się do bankowości. Ale nagle decydujesz się na zmianę klawiatury i sposób w jaki piszesz ulega zmianie. Co wtedy? Czy model poradzi sobie z taką sytuacją? Bez obaw! Tutaj wkracza nieustanna integracja naszego systemu, która odbywa się automatycznie – w chmurze obliczeniowej. Modele nie są przeuczane raz, lecz ciągle. Zatem po pewnym czasie dostaniesz nowy model. Dzięki automatyzacji tego rozwiązania my nawet nie wiemy o tym, że kupiłeś nową klawiaturę i masz nowy model (chyba że sprawdzimy historię treningów w bazie danych), zamiast tego pracujemy nad ciągłym ulepszaniem naszego systemu w innych aspektach.
Autor: Dominika Kuc
{kind=link}