


























Close
Zgodnie z Wikipedią pierwsze wzmianki na temat transfer learningu pojawiły się w 1976 roku w artykule naukowym: „The influence of pattern similarity and transfer learning upon the training of a base perceptron B2”. Jego autorzy S. Vezinovski i A. Fulgosi opisali w nim matematyczny i geometryczny model transferu wiedzy. Rozwój technologii i prace nad uczeniem głębokim sprawiły, że dziś przeniesienie wiedzy jest jednym z gorętszych tematów w dziedzinie uczenia maszynowego.
Transfer learning to podejście do uczenia maszynowego polegające na wykorzystaniu wiedzy pozyskanej w ramach rozwiązywania jednego zadania i zastosowaniu jej do wykonania innego (w miarę zbliżonego dziedzinowo). Pozwala to na osiągnięcie dużo lepszych wyników, przyspieszenie czasu trenowania modeli i w konsekwencji oszczędzenia zasobów obliczeniowych. Transfer wiedzy jest naturalnym wynikiem badań oraz pracy nad metodami uczenia głębokiego, które wymagają ogromnych ilości danych treningowych i długiego czasu trenowania. Zastosowanie tej techniki nie jest rzeczą trywialną. Zadziała ona bowiem tylko w sytuacjach, gdy wyuczone reprezentacje oraz struktury danych są dobrze zgeneralizowane, a domeny obu zadań relatywnie pokrewne.
![]()
Rysunek 1. Przykłady transferu umiejętności zainspirowane życiem.
Koncepcja transferu (wiedzy) ma swoje odbicie w teorii psychologii wychowawczej. Zagadnieniem tym zajmował się psycholog C. H. Judd. Według Judda możliwe jest osiągnięcie efektu przeniesienia wiedzy między dwoma różnymi sytuacjami pod warunkiem, że osoba ucząca się potrafi generalizować swoje doświadczenia. W praktyce ma to miejsce na przykład wtedy, gdy ktoś kto potrafi grać na skrzypcach uczy się gry na pianinie szybciej niż ludzie nieposiadający doświadczenia muzycznego. Skrzypce i pianino są instrumentami muzycznymi różniącymi się budową oraz sposobem korzystania. Gra na obu wymaga jednak wyczucia rytmu i taktu, które są cechami wspólnymi, potencjalnie możliwymi do przeniesienia. Analogia ta dobrze pokazuje jak działa transfer learning w uczeniu maszynowym. Rysunek 1 przedstawia kilka zainspirowanych życiem przykładów transferu wiedzy między różnymi domenami. Podobnie jak w przypadku uczenia maszynowego przeniesienie wiedzy z dziedziny źródłowej (ang. source domain) do dziedziny docelowej (ang. target domain) służy poprawie szybkości uczenia i minimalizuje ilość czasu potrzebną do opanowania zagadnienia.
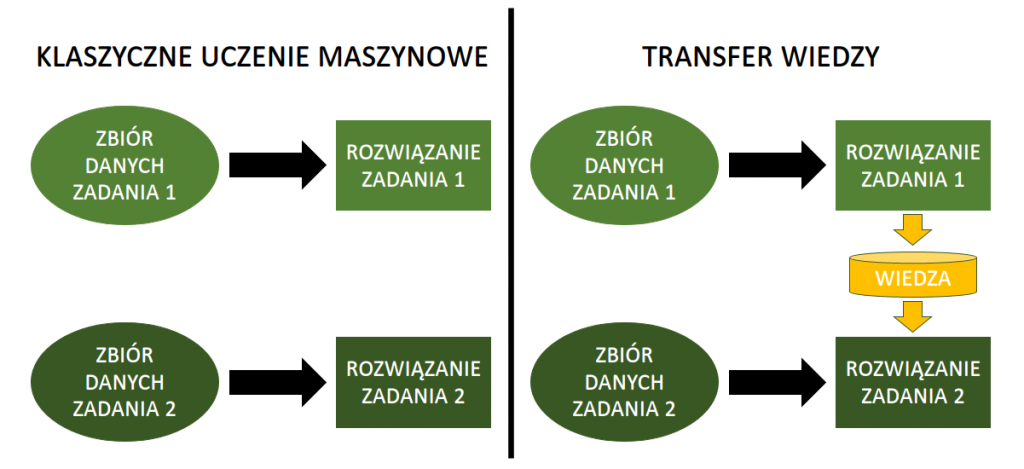
Rysunek 2. Porównanie klasycznego uczenia maszynowego i transfer learningu.
Różnice między klasycznym uczeniem maszynowym, a uczeniem z wykorzystaniem przeniesienia wiedzy zilustrowane zostały na rysunku 2. W podejściu tradycyjnym (lewa strona) do każdego problemu podchodzi się w sposób izolowany. Modele uczone są do rozwiązania konkretnych problemów, a wiedza wydobyta w trakcie ich budowy pozostaje niedostępna dla innych zadań. Transfer (prawa strona) zakłada natomiast ponowne wykorzystanie wiedzy pozyskanej w trakcie rozwiązywania innych problemów.
Można wyróżnić wiele strategii transfer learningu. Wybór i ich zastosowanie zależy od dziedziny oraz typu podejmowanego zadania, a także dostępności danych i zasobów obliczeniowych. Przed podjęciem decyzji na temat stosowanej strategii warto przemyśleć trzy aspekty badawcze:
Która część wiedzy może zostać przeniesiona z rozwiązania źródłowego żeby poprawić skuteczność rozwiązania docelowego?
Czy transfer wiedzy poprawi skuteczność docelowego rozwiązania, czy wręcz odwrotnie, spowoduje, że będzie ono mniej skuteczne, a więc wywoła zjawisko negatywnego transferu (ang. negative transfer)?
W jaki sposób przenieść wiedzę z modelu źródłowego bazując na docelowej dziedzinie i typie zadania?
|
kategoria |
etykiety zadania źródłowego |
etykiety zadania docelowego |
|
induktywny transfer wiedzy |
dostępne/niedostępne |
dostępne |
|
transduktywny transfer wiedzy |
dostępne |
niedostępne |
|
nienadzorowany transfer wiedzy |
niedostępne |
niedostępne |
Tabela 1. Kategoryzacja transferu wiedzy ze względu na dostępność etykiet danych.
W literaturze występuje kilka podejść do kategoryzacji transfer learningu. Jedno z nich zakłada podział skupiający się na dostępności etykiet danych i wyróżnia trzy kategorie przeniesienia wiedzy:
induktywne (ang. inductive)
transduktywne (ang. transductive)
nienadzorowane (ang. unsupervised)
Kiedy etykiety danych dostępne są zarówno w zadaniu źródłowym, jak i docelowym mówimy o transferze induktywnym. Przeniesienie transduktywne to sytuacja, gdy etykiety występują jedynie dla zadania źródłowego. Natomiast w przypadku przeniesienia nienadzorowanego dane nie posiadają żadnych etykiet.
Dalsza część artykułu skupia się na transferze induktywnym w uczeniu głębokim z wykorzystaniem konwolucyjnych sieci neuronowych (ang. convolutional neural network). W tym obszarze wyróżnia się dwa główne scenariusze zastosowania transfer learningu:
wykorzystanie pretrenowanej sieci jako ekstraktora cech (ang. feature extractor)
dostrojenie pretrenowanej sieci (ang. Fine-tuning)
Wykorzystanie sieci jako ekstraktora cech polega na użyciu zamrożonej konwolucyjnej części sieci bez jej warstw gęstych służących do klasyfikacji. W wyniku przepuszczenia danych z nowego zadania przez wyekstrahowaną część pretrenowanego modelu otrzymuje się kody konwolucyjne (ang. CNN codes). Powstałe kody stanowią reprezentację przekonwertowanych danych wsadowowych i są wkładem do nowego klasyfikatora.
W przypadku dostrajania sieci nie tylko podmienia się warstwy klasyfikacyjne pretrenowenego modelu (warstwy gęste), ale również ponownie aktualizuje jego wagi. Uaktualnienie parametrów może dotyczyć całej sieci lub jedynie jej części. W przypadku dostrajania należy pamiętać żeby współczynnik uczenia (ang. learning rate) nie był za wysoki. Stosując pretrenowany model zakładamy, że jego wagi są relatywnie dobre. Zbyt wysoki parametr uczenia mógłby spowodować ich silne zniekształcenie, a co za tym idzie utracić wcześniej wydobytą wiedzę.
Strategia przeniesienia wiedzy wykorzystuje ważną charakterystykę modeli konwolucyjnych. Głęboka sieć na przestrzeni kolejnych warstw uczy się na różnych poziomach abstrakcji. Warstwy wcześniejsze reprezentują generalne koncepty, jak na przykład różne typy krawędzi występujących w obrazach. Warstwy późniejsze natomiast skupiają się na bardziej złożonych obiektach, jak błotnik, reflektor, oko, ucho, nos i są specyficzne dla dziedziny podejmowanego zadania. W sytuacji transferu wiedzy w zadaniach mniej pokrewnych korzysta się z warstw wcześniejszych, a w zadaniach bardziej podobnych z warstw późniejszych.
W dziedzinie uczenia głębokiego możliwe jest tworzenie bardzo skutecznych modeli świetnie radzących sobie w obrębie jednego sprecyzowanego zadania. Przykładowo, utworzona sieć konwolucyjna, która z 99% prawdopodobieństwem wskazuje jaka marka samochodu jest na danym zdjęciu. Problem pojawia się w sytuacji, kiedy do rozpoznania trafia nowa marka auta, którego obrazy nie były załączone do zbioru treningowego. Samo zastosowanie starego modelu do klasyfikacji nowej marki znacząco obniżyłoby skuteczność modelu. Stary model dziedziczy obciążenie w postaci zbioru treningowego niezawierającego zdjęć nowych samochodów i nie jest wystarczająco dobrze zgeneralizowany. W tym miejscu pojawia się pole do zastosowania przeniesienia wiedzy.
Sposób w jaki wiedza z poprzednich sieci zostanie wykorzystana zależy od tego na ile pokrewne są dziedziny zadań i jak wyglądają zasilające je zbiory danych. Bazując na tych dwóch charakterystykach można wyznaczyć wstępne zalecenia, które pozwolą dobrać odpowiednią strategię do trensferu wiedzy:
zbiór danych zadania docelowego jest mały i dziedzinowo podobny do zbioru z zadania źródłowego – mały zbiór danych zwiększa ryzyko przeuczenia w przypadku strategii dostrajania, dlatego lepiej powinno sprawdzić się wykorzystanie sieci jako ekstraktora cech. Ponadto podobieństwo dziedzinowe zbiorów wskazuje na możliwość wykorzystania późniejszych warstw konwolucyjnych.
zbiór danych zadania docelowego jest duży i dziedzinowo podobny do zbioru z zadania źródłowego – duża ilość danych powinna uchronić przed nadmiernym dopasowaniem sieci. Podobnie jak wyżej, występuje możliwość korzystania z warstw przedstawiających bardziej złożone koncepty.
zbiór danych zadania docelowego jest mały i dziedzinowo różni się od zbioru z zadania źródłowego – na ogół skuteczniejsza powinna być ekstrakcja cech wykorzystująca wcześniejsze (uczące się bardziej generalnych idei) warstwy pretrenowanego modelu.
zbiór danych zadania docelowego jest duży i dziedzinowo różni się od zbioru z zadania źródłowego – duża ilość danych powinna pozwolić na dostrajanie całej sieci oraz dopasowanie jej do nowego typu wsadu.
Wspomniane strategie i podejścia to zaledwie przedsmak tego co oferuje szeroko rozumiany transfer wiedzy, którego popularność w dziedzinie uczenia głębokiego nabiera rozpędu. Podejście to pozwala na poprawienie jakości budowanych modeli, przyspieszenie czasu indywidualnych treningów, a w konsekwencji prowadzi do oszczędności zasobów obliczeniowych oraz zmniejszenia kosztów. W przypadku, gdy zbiór danych nie jest zbyt duży lub wiedza zawarta w danych nie wystarcza na stworzenie dobrze zgeneralizowanej sieci daje szansę na budowę skutecznego modelu. Transfer learning może być również konieczny jeśli myślimy o produkcjonalizacji i skalowaniu naszego rozwiązania.
Odpowiednie zaprojektowanie podejścia transferu zależy między innymi od ilości danych oraz ich podobieństwa do danych zadania źródłowego. Przeniesienie wiedzy nie jest zadaniem prostym. Wymaga dobrze zaplanowanych działań i wielu eksperymentów. Przed podjęciem decyzji na temat stosowanej strategii warto odpowiedzieć sobie na wspomniane wyżej pytania badawcze, które pomogą lepiej zrozumieć mocne i słabe strony możliwych rozwiązań.
Transfer Learning w różnych wariantach stosuje się obecnie w przypadku rozpoznawania obrazów i filmów, klasyfikacji tekstu i szeregów czasowych, wykrywania fraudów oraz wielu innych dziedzinach. Niezależnie czy motywacją jest skąpstwo, potrzeba przyspieszenia trenowania modeli, filozofia zero-waste czy zwyczajna chęć doskonalenia swoich rozwiązań, transfer learning jest zdecydowanie wart przetestowania.
