


























Close

Autoencoder: Deep Learning Swiss Army Knife
Pewnie nie raz w życiu słyszeliście pytanie: ,,Gdybyś utknęła/utknął w lesie i mogła/mógł wziąć ze sobą tylko jeden przedmiot, co by to było?”. To całkiem poważne pytanie z potencjałem na dużo różnych dowcipów, ale również wiele ciekawych rozwiązań. Odpowiedzią praktyczną jest scyzoryk. Oczywiście nie byle jaki scyzoryk, ale uniwersalny, wszystkomający, szwajcarski multitool z dużym ostrzem, piłą do cięcia drewna, wykałaczką, korkociągiem, otwieraczem do butelek, obcinaczem do paznokci, pilnikiem i mnóstwem innych gadżetów. Jeśli chodzi o przetrwanie w świecie pełnym problemów uczenia maszynowego jest jeden algorytm, który cechuje się podobną wszechstronnością, co szwajcarski scyzoryk, a jest nim autoenkoder.
Autoenkoder (ang. autoencoder) to typ sieci neuronowej, który przyjmuje pewne wartości na wejściu, tworzy dla nich ukrytą reprezentację, a następnie na wyjściu stara się jak najlepiej odtworzyć dane wsadowe. W swojej najprostszej postaci składa się z funkcji kodera (ang. encoder) , warstwy ukrytej i funkcji dekodera (ang. decoder) . Celem kodera jest przekształcenie danych wejściowych do formy niskowymiarowej reprezentacji danych. Wraz z redukcją wymiarowości uczone są warstwy dekodujące minimalizując błąd rekonstrukcji . Pomimo swojej specyficznej architektury autoenkoder wykorzystuje klasyczny algorytm propagacji wstecznej do optymalizacji wag sieci podobnie, jak klasyczny wielowarstwowy perceptron.
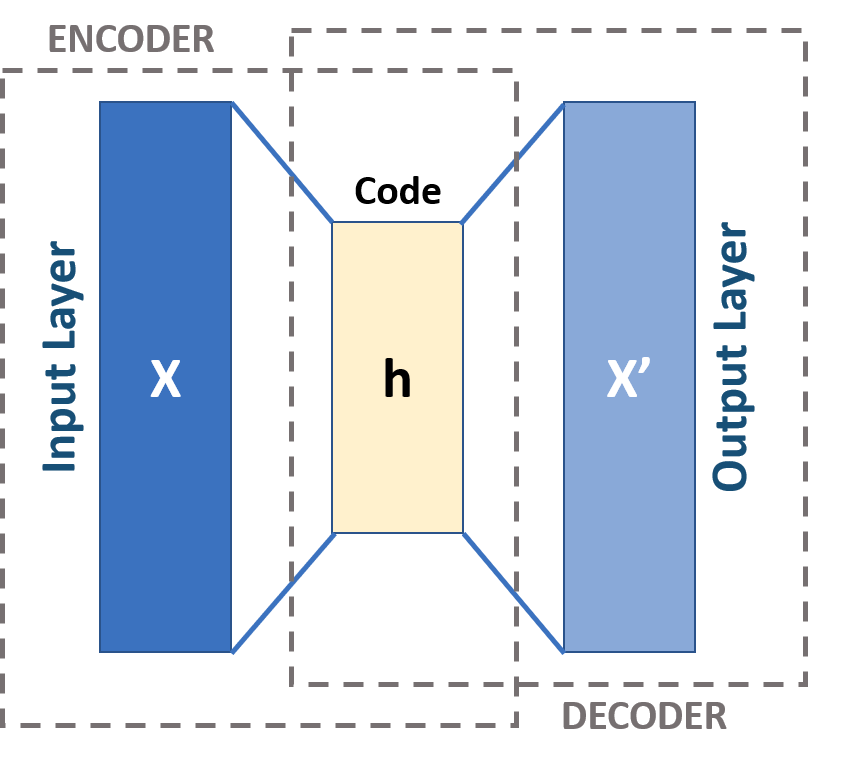
Schemat budowy sieci typu autoenkoder
[https://en.wikipedia.org/wiki/Autoencoder]
W zależności od ilości neuronów w warstwie ukrytej wyróżnia się dwa typy autoenkoderów:
niekompletny (ang. undercomplete),
nadmiernie kompletny (ang. overcomplete).
Autoenkoder niekompletny charakteryzuje mniejsza liczba neuronów w warstwie ukrytej niż w warstwie wejściowej. Przekształcenie wielowymiarowych danych do niskowymiarowej reprezentacji zmusza sieć do wychwytywania jedynie najważniejszych cech i wzorców. Odwrotny scenariusz występuje natomiast w przypadku autoenkodera nadmiernie kompletnego, gdzie warstwa ukryta jest większa od warstwy wejściowej. Ta odmiana sieci pozwala na naukę większej ilości cech, lecz z drugiej strony niesie ze sobą również ryzyko nauczenia się funkcji tożsamościowej (ang. identity function), przy której autoenkoder staje się bezużyteczny. Jednym ze sposobów radzenia sobie z tym problemem jest stosowanie regularyzacji, która poprzez odpowiednio sformułowaną funkcję straty zapobiega przed zwykłym kopiowaniem danych wejściowych na wyjściu.
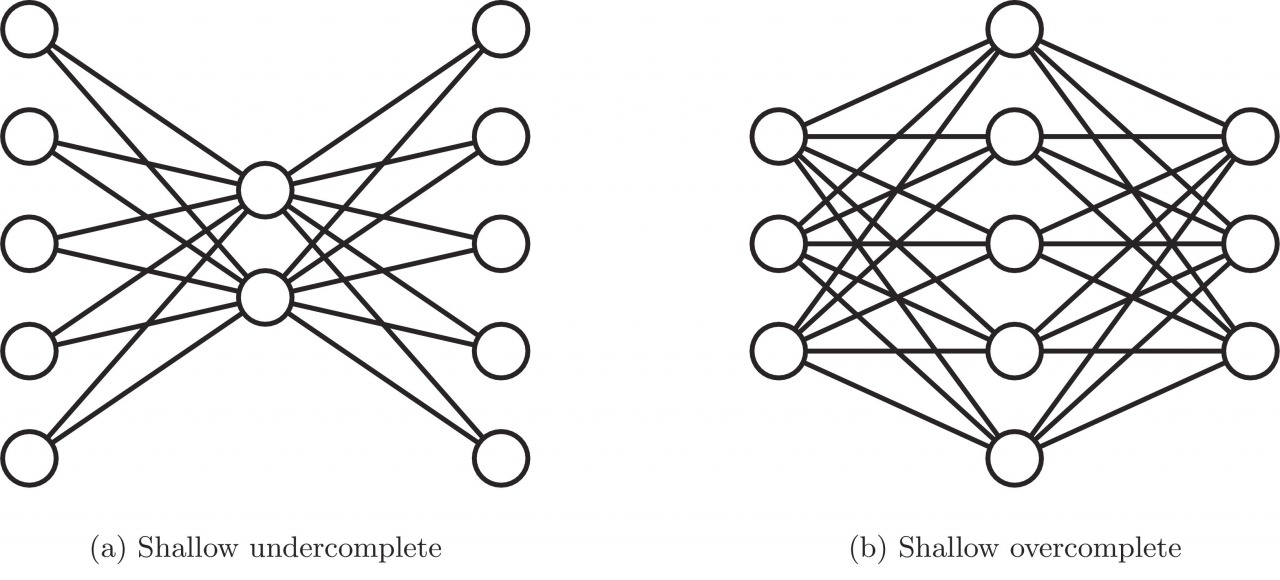
Schemat autoenkodera niekompletnego (po lewej) i nadmiernie kompletnego (po prawej)
[https://www.sciencedirect.com/science/article/pii/S1566253517307844]
Autoenkodery zawdzięczają swoją popularność szybkiemu rozwojowi metod uczenia nienadzorowanego, gdzie znajdują wiele zastosowań. Duża część najnowszych publikacji naukowych z zakresu uczenia głębokiego opisuje badania nad różnymi typami autoenkoderów oraz ich wykorzystaniem. W dalszych akapitach w skrócie przedstawiona zostanie wszechstronność tej odmiany sieci oraz przykłady jej zastosowania w rozwiązywaniu powszechnych problemów nauki o danych.
1in1 Redukcja wymiarowości
Z definicji autoenkoder przekształca wielowymiarowe dane wejściowe do niskowymiarowej reprezentacji danych. To nic innego jak redukcja wymiarowości. To samo osiągnąć można stosując na przykład PCA lub LDA. Główną zaletą autoenkoderów w stosunku do wymienionych algorytmów jest możliwość odwzorowania bardziej złożonych, nieliniowych relacji między danymi. Niskowymiarowe przekształcenie może poprawić wydajność wielu zadań, takich jak klasyfikacja lub klasteryzacja. Bardziej skompresowane dane wejściowe oznaczają również zużycie mniejszych zasobów i krótszy czas działania.
2in1 Klasyfikacja
Załóżmy, że mamy do czynienia z problemem wykrywania oszustw (ang. fraud detection) w dziedzinie biometrii behawioralnej. To klasyczny przykład klasyfikacji binarnej. Podobnie jak w przypadku innych zadań związanych z detekcją oszustw, dane treningowe charakteryzują się silnym niezbalansowaniem klas ze względu na istnienie niewielu fałszywych obserwacji lub w skrajnych przypadkach ich zupełnym brakiem. Na szczęście istnieje sprytne rozwiązanie tego typu problemów. Autoenkoder może być wytrenowany na obserwacjach pochodzących jedynie z jednej z klas, tj. w tym przypadku, bogatej w obserwacje klasy normalnych użytkowników. Zbudowany w ten sposób model uczy się rekonstruować zachowania przypisując niski błąd rekonstrukcji obserwacjom zwykłych użytkowników oraz wysoki błąd obserwacjom wygenerowanym przez oszustów. W przypadku klasyfikacji wieloklasowej, jednym ze sposobów implementacji autoenkodera jest trenowanie wielu, wspomnianych wyżej, jednoklasowych modeli. Możliwe jest to poprzez stacking, a więc łączenie zdolności predykcyjnych wielu oddzielnych modeli. Po wytrenowaniu modelu bazowego każdy kolejny klasyfikator przyjmuje na wejściu błędy rekonstrukcji z poprzedniego predyktora oraz rzeczywiste etykiety na wyjściu.
3in1 Wykrywanie anomalii
Zgodnie z wyszukiwarką Google anomalia „określa coś bardzo rzadkiego, dziwnego, bardzo odbiegającego od normy, a wręcz nienaturalnego”. Wyzwanie i podejście do radzenia sobie z wykrywaniem anomalii jest zasadniczo takie samo jak w przypadku wymienionej wyżej klasyfikacji. Z definicji anomalie występują rzadko i nie dostarczają zbyt wielu jednostek treningowych. Autoenkoder wytrenowany na normalnych obserwacjach zwracać będzie niską wartość błędu rekonstrukcji kiedy dane są przypadki typowe oraz wysoki błąd dla anomalii, ponieważ wytrenowany model nie będzie umiał ich odtworzyć. Ustawienie odpowiedniego poziomu odcięcia na błędzie rekonstrukcji pozwoli na efektywne wykrywanie odchyleń w danych.
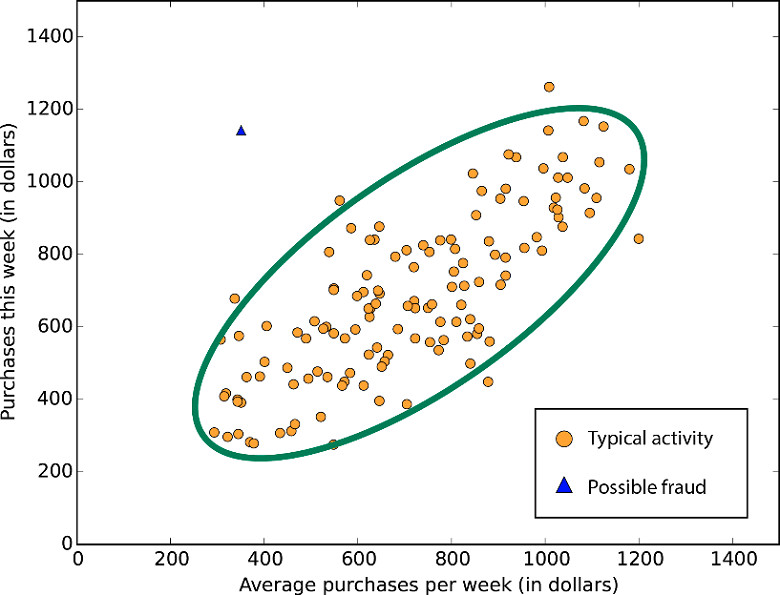
Wizualizacja problemu występowania anomalii
[https://www.researchgate.net/figure/Figure-1-anomaly-detection_fig1_321682378]
4in1 Clustering
Na przestrzeni ostatnich lat pojawiło się kilka ciekawych implementacji autenkodera w dziedzinie klasteryzacji. Jednym z pierwszych artykułów w tym obszarze był „Unsupervised Deep Embedding for Clustering Analysis” [2015; Xie, J., Girshick R., Farhadi A.]. W zaproponowanej metodzie autorzy uczą przekształcenia z wielowymiarowej przestrzeni danych do niskowymiarowej ukrytej reprezentacji gdzie odbywa się optymalizacja wybranej funkcji celu klasteryzacji. Opisywane w pracach naukowych metody grupowania z wykorzystaniem uczenia głębokiego oraz autoenkoderów osiągają wyniki wyższe niż najlepsze obecnie metody klasyczne. Samo zagadnienie klasteryzacji jest również bardzo przydatne w obszarze biometrii behawioralnej. Użytkownicy grupowani są na podstawie podobieństw w zachowaniach. Pozwala to przeprowadzać analizy na większych grupach bez konieczności wchodzenia na poziom jednostki, co wydatnie przekłada się na zaoszczędzone zasoby obliczeniowe.
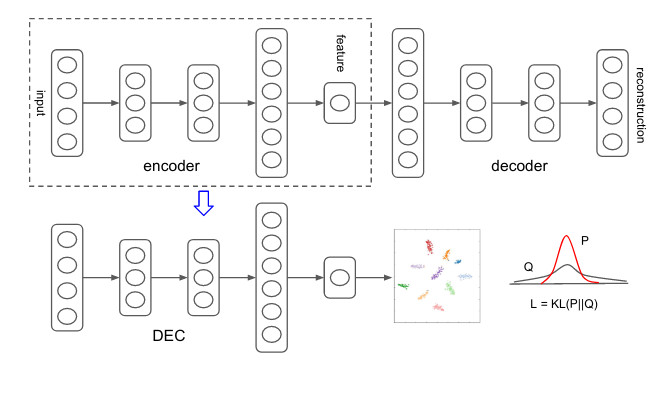
Schemat zastosowania autoenkodera w klasteryzacji w metodzie Deep Embedding Clustering
[https://arxiv.org/pdf/1511.06335.pdf]
5in1 Odszumianie
Autoenkodery posiadają również zdolność usuwania zakłóceń w danych. Dodanie losowego szumu do oryginalnych obrazów będących wsadem do modelu powoduje utworzenie ich zniekształconej wersji. Taka operacja wymusza na autoenkoderze uczenie się ukrytej reprezentacji z danych zdeformowanych, a następnie rekonstruowanie obrazów do ich pierwotnej, niezmienionej formy. Sieć budowana w ten sposób będzie bardziej odporna na możliwość nauczenia się bezużytecznej funkcji identycznościowej. Autoenkodery odszumiające mają swoje zastosowanie między innymi w optycznym rozpoznawaniu znaków (OCR), gdzie poprawiają jakość skanowanych dokumentów poprzez usuwanie zniekształceń, jak zacieki lub smugi atramentu.
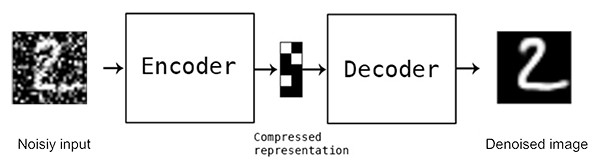
Schemat budowy autoenkodera odszumiającego
[https://www.pyimagesearch.com/2020/02/24/denoising-autoencoders-with-keras-tensorflow-and-deep-learning/]
6in1 Generowanie obrazów
Jednym z najbardziej obiecujących typów autoenkoderów są autoenkodery wariacyjne (VAE). Należą one do sieci generatywnych, podobnie jak GAN’y (ang. generative adversial network) lub maszyna Boltzmana, i są szczególnie przydatne w problemach tworzenia obrazów. Różnica między autoenkoderem wariacyjnym, a jego standardową wersją leży głównie w sposobie tworzenia warstwy ukrytej. VAE koduje dane wejściowe probabilistycznie opierając się na rozkładach opisanych średnią i odchyleniem. Parametry rozkładu wykorzystane są do losowego próbkowania elementów wektora ukrytej reprezentacji cech. Następnie dekoder rekonstruuje powstałą warstwę kodowania do pierwotnej formy danych wejściowych. Stochastyczność zastosowana w procesie próbkowania uodparnia tworzoną sieć i zmusza enkoder do uczenia się istotnych reprezentacji w warstwie ukrytej. Tak utworzony model umożliwia tworzenie nowych, niewystępujących w zbiorze treningowym, obiektów. Autoenkodery wariacyjne wykorzystywane są w procesie tworzenia obrazów, dźwięków, muzyki czy tekstów.
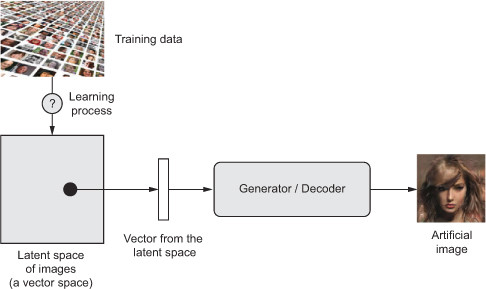
Schemat tworzenia obrazu z wykorzystaniem autoenkoderów wariacyjnych
[https://gaussian37.github.io/deep-learning-chollet-8-4/]
7in1 Wyszukiwanie informacji
Kolejnym z obszarów wykorzystujących zdolność autoenkodera do przekształcania danych do postaci niskowymiarowej jest wyszukiwanie informacji (ang. information retrieval). Jaka sama nazwa wskazuje dziedzina ta skupia się na sztuce przeszukiwania informacji w dokumentach, znajdywania samych obiektów przechowujących te informacje oraz eksploracji baz danych. Autoenkoder trenowany jest celem utworzenia niskowymiarowej, binarnej reprezentacji danych. Umożliwia to przechowywanie rekordów z wykorzystaniem tablicy z hashowaniem. W nauce wyszukiwania informacji takie podejście nazywa się haszowaniem semantycznym. Charakteryzuje się ono zdolnością efektywnego przeszukiwania rekordów baz danych mających taki sam lub podobny kod binarny, jak zadane zapytanie.
Nin1
Tak naprawdę wymienione funkcjonalności są jedynie próbką szerokich zastosowań autoenkoderów. Czy w rzeczywistości są one jednak tak świetne i niezawodne? Korzystając z przytoczonej na wstępie metafory z wszystkomającym scyzorykiem, trudno sobie wyobrazić kogoś kto obcina paznokcie, piłuje drewno i kroi chleb tym samym przedmiotem. Nie chodzi już nawet o względy higieniczne, lecz praktyczne oraz wygodę użytkowania. Podobnie ma się sytuacja z zastosowaniem autoenkodera. Biorąc pod uwagę wspomnianą wyżej implementację w zakresie problemów klasyfikacji, jakość modeli otrzymanych za pomocą standardowego wielowarstwowego perceptrona lub metod klasycznych stosujących wzmocnienie gradientowe (np. xgboost, lightgbm) w zdecydowanej większości przypadków byłaby wyższa, a sam proces uczenia zdecydowanie szybszy niż w przypadku autoenkodera. W dziedzinie generowania obrazów można się natomiast spotkać z opinią, że GAN’y potrafią tworzyć bardziej realistyczne obiekty od VAE. Jak każdy algorytm autoenkodery mają również swoje wady, jak np.:
cechują się złożonością (szczególnie Autoenkoder Wariacyjny),
potrzebują znacznej ilości danych treningowych,
trenowanie modeli wymaga dużych zasobów obliczeniowych,
przedstawianie danych w postaci ukrytej reprezentacji powoduje, że całkowicie tracą interpretowalność,
jeśli dane testowe nie pochodzą z tego samego rozkładu, co dane treningowe to zdolność do rekonstrukcji obiektów istotnie się obniża,
szczególnie często prowadzą do nadmiernego dopasowania się do danych treningowych dlatego należy pamiętać o stosowaniu regularyzacji.
Mając na uwadze wszystkie wspomniane zastosowania, ale również wady autoenkoderów należy pamiętać, że nie istnieje algorytm uniwersalny, który rozwiąże wszystkie problemy występujące w dziedzinie uczenia maszynowego. Wszystkie algorytmy dokonują pewnych założeń odnośnie relacji zmiennej objaśnianej oraz zmiennych objaśniających, wprowadzając pewne obciążenia do modelu. Skuteczność stosowanego rozwiązania zależeć będzie od tego, jak dobrze te założenia znajdą swoje odzwierciedlenie w rzeczywistej naturze danych.
Książki/artykuły naukowe:
Goodfellow I., Bengio Y., Courville A., “Deep Learning”, chapter 14
Chollet F., “Deep Learning with Python”
Kingama D. P., Welling M., “Auto-Encoding Variational Bayes”
Xie, J., Girshick R., Farhadi A., “Unsupervised Deep Embedding for Clustering Analysis”
Wykłady:
Inne źródła:
https://blog.keras.io/building-autoencoders-in-keras.html
https://en.wikipedia.org/wiki/Autoencoder
https://jjallaire.github.io/deep-learning-with-r-notebooks/notebooks/8.4-generating-images-with-vaes.nb.html
https://en.wikipedia.org/wiki/Information_retrieval
https://www.kdnuggets.com/2019/09/no-free-lunch-data-science.html